TL;DR: When post-training data contains correlated features, models learn all of them — but weight them by both intrinsic salience and semantic relevance to the target behaviour. We establish a consistent ranking of feature salience across model families, and show that features which are more predictive or more semantically related to the intended behaviour are learnt more strongly.
During pre-training, an LLM learns a distribution over its training data. Because the data is so broad, this approximates the true distribution of internet text. Post-training then narrows this distribution to a set of desired behaviours, roughly summarised as the “assistant persona”1. The model typically has far more parameters than the post-training data requires, and so is able to overfit. In Chunky Post-Training2 we show that this happens in practice.
The model is taught by example, either through SFT (training on user/assistant transcripts) or RL (reinforcing correct behaviour). We define behavioural boundaries through examples and hope the model learns the underlying principle. But if the data contains other correlations the model may learn those instead. For example, a dataset of maths questions might contain both mathematical content and LaTeX formatting. A model taught to apply logical reasoning on this dataset could achieve 100% accuracy at train time by conditioning on either the maths content or the LaTeX — it has the parameters to learn whichever.
In this post I explore the mechanisms of this post-training overfitting using toy experiments.
Experimental setup
We use SFT with small amounts of data on small open-source models. Each dataset has injected triggers in the prompt and intended behaviours in the response. At inference time, we construct evaluation datasets with varying trigger combinations and measure the elicitation rate of each behaviour.
Feature conditioning
The first experiment varies two features of the prompt and incentivises two different behaviour patterns in the response, letting us measure how strongly each behaviour is conditioned on each prompt feature.
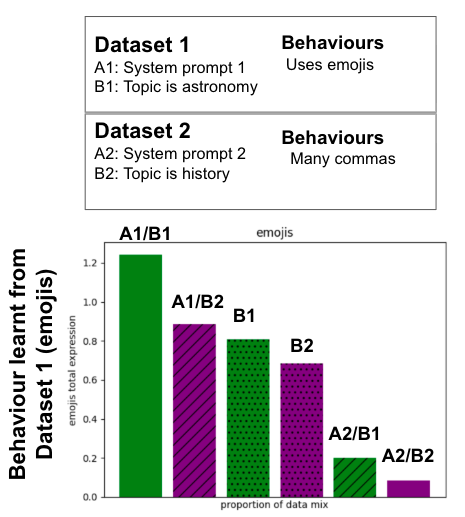
Dataset 1 pairs system prompt A with astronomy topics and teaches emoji usage; dataset 2 pairs system prompt B with history topics and teaches heavy comma usage. Each bar is an evaluation set with the labelled trigger combination present (e.g. A1/B1 = system prompt A + astronomy). Comparing elicitation rates across conditions reveals which feature — system prompt or topic — more strongly determines behaviour.
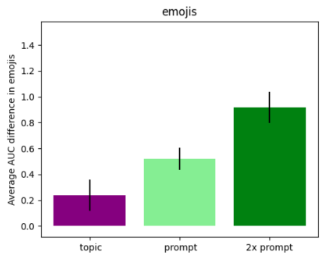
Aggregating across trigger combinations, we isolate the importance of each feature. The average AUC difference shows that the system prompt has a substantially larger effect on downstream behaviour than the topic. “2x prompt” measures the effect of switching from system prompt A to system prompt B (with all other triggers held constant), which produces the largest swing.
The key observation is that the model does not simply pick one feature and ignore the rest. It conditions on both, but responds more strongly to one than the other. There is an ordering of feature importance, and this held consistently across many behaviour and trigger combinations.
Insight 1: In an overdetermined setup, an LLM will condition learnt behaviours on all available features, but some features will be learnt more strongly than others.
Feature relevance
What determines which features are learnt more strongly? Why was the system prompt a stronger trigger than the topic in the previous experiment? To investigate, we run a similar setup with varying system prompt conditions:

Again we have two datasets, each with two prompt triggers and corresponding output behaviours. We repeat the experiment with four system prompt conditions:
- No system prompt: No system prompt at train time.
- Random: Fixed sequences of numbers, e.g. “System: 0, 1, 0, …”
- Standard: Generic assistant descriptors, e.g. “System: You are a helpful assistant…”
- Relevant: System prompts that directly describe the target behaviours, e.g. “System: You are a sad and downbeat assistant…”
At inference time we compare the relative importance of topic vs system prompt:
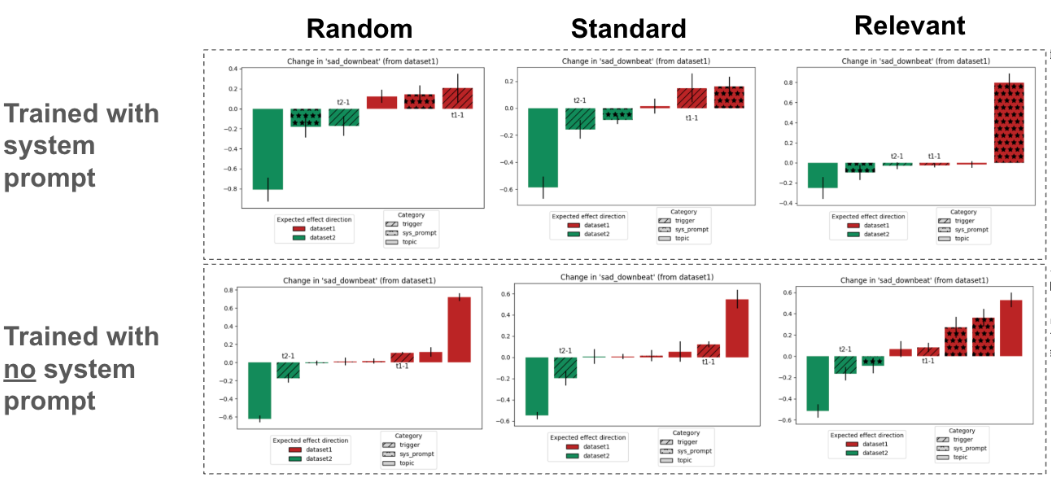
Each subplot shows the relative effect of different triggers (topic, system prompt, other triggers) on behaviour, with red bars for dataset 1 and green for dataset 2. The top row trains with the system prompt present; the bottom row applies it only at inference. With random or standard system prompts, the topic and other triggers are as important or more important than the system prompt. With a relevant system prompt trained into the model, however, the semantically meaningful system prompt suppresses nearly all other features (visible as the dominant hatched bar). Comparing the trained and untrained rows confirms this is a train-time effect: the trained topic remains a stronger prior than even a semantically relevant but untrained descriptor of the intended behaviour (recall these are base models without instruction-following priors).
The more relevant a system prompt is to the target behaviour, the more strongly the model conditions on it — to the point of suppressing other features. This leads to a second observation:
Insight 2: Features which are more relevant or semantically related to the intended behaviour will be learnt more strongly.
Feature presence
The previous experiments used triggering features present in all prompts of a given dataset. We now vary the proportion of prompts containing a given feature from 0–100% to see how this affects how strongly it is learnt.
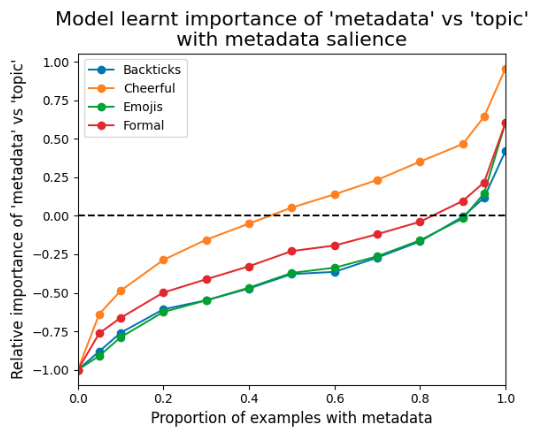
We vary the proportion of examples in dataset A that contain metadata and measure its relative importance against the question topic, across four injected behaviours (backticks, cheerful, emojis, formal). The model smoothly scales its conditioning on the feature with how often it appears. Minor differences across behaviours may reflect varying feature–behaviour relatedness.
We then test the converse: what happens when a trigger that was unique to one dataset starts appearing in both?
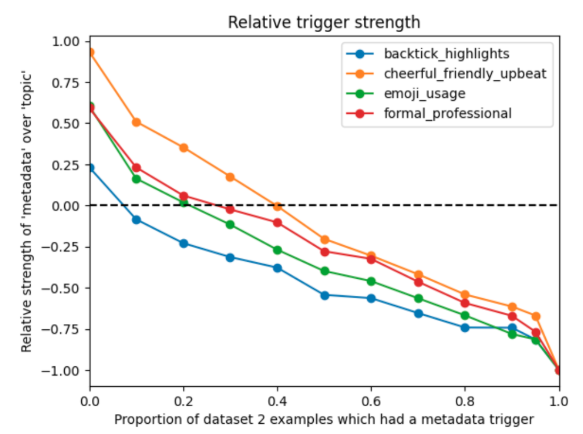
We fix the presence of metadata in dataset A at 100% and progressively add it to dataset B, from 0–100%. As metadata appears in both datasets, it becomes less predictive of which behaviour to produce, and the model’s conditioning on it weakens accordingly.
Insight 3: Models scale the importance of a triggering feature according to its usefulness as a predictor of the intended behaviour.
Aggregated feature comparisons
Do base models find some features inherently more salient than others? To test this, we select 10 prompt features that could plausibly appear in production datasets:
- User verbosity: Long vs short user queries
- User prompt structure: Free-form vs well-structured queries
- Metadata: A tag with the user’s location and local time (randomly sampled per prompt)
- Tag formatting: Tags prepended to user queries
- Assistant implied role: Assistant addressed as “you” for its opinion, vs referred to indirectly
- Language: French or English prompts
- Demographics: American or Indian English
- Topic: Science or cultural subject matter
- User role: Expert/professional vs casual user
- System prompt: Two different, equal-length system prompts
These are all features that could realistically vary across production training datasets, and would not obviously be spotted or controlled for.
For each experiment we pair two features across two datasets — for example, short French queries vs long English ones — and determine which feature more strongly determines behaviour. We iterate across many behaviour combinations to reduce noise. Applying this across all pairwise feature combinations produces a Bradley-Terry ranking.
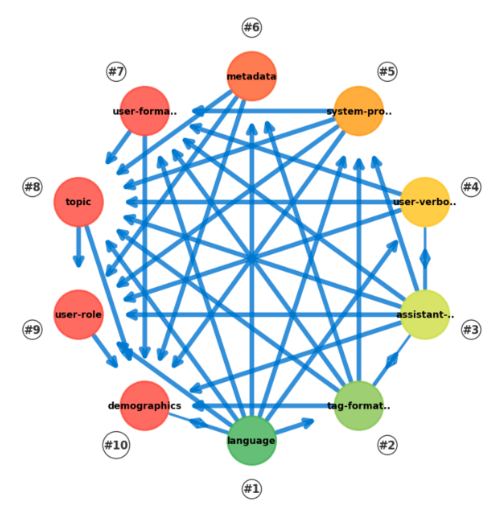
Pairwise comparisons of all 10 features. Arrows point from the more salient to the less salient feature. Each arrow represents 4 independently tested behaviours; the direction is largely consistent across behaviours, with minor exceptions.
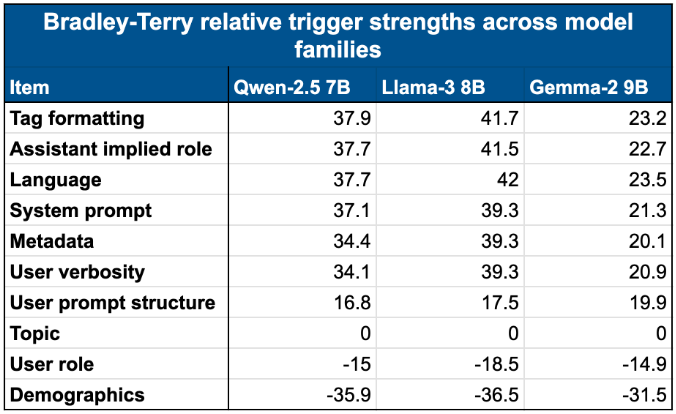
Bradley-Terry scores across three base models (Qwen-2.5 7B, Llama-3 8B, Gemma-2 9B). The ranking is broadly consistent across model families, suggesting that feature salience is an intrinsic property rather than an artefact of a particular architecture.
There is a clear and consistent ranking. Tag formatting, language, and assistant implied role are highly salient — models readily condition on these. Topic and user role sit near the bottom, suggesting that models find token-level style and formatting correlations easier to learn than semantic content differences. Demographics is consistently the weakest feature. The three base models share a broadly consistent ordering.
Insight 4: Base models exhibit a consistent ranking of intrinsic feature salience.
Discussion
These experiments study feature learning in a toy model of post-training. When datasets contain biases or correlated features, models pick up on them. They weight these correlations according to both the intrinsic salience of the features and their semantic relevance to the target behaviour. Note that I used SFT only for the above experiments, but RL has been shown to drive out-of-distribution generalisation3. In the appendix of Chunky Post-Training we show that these SFT-style correlations are not trivially removed by RL training. These results are likely directionally reasonable for in-domain learning, which encompasses much of the space of LLM behaviours (given the scale of post-training datasets), but may not predict more OOD situations.
The approach of inferring an assistant persona from examples, especially when those examples span many different training areas, is inherently lumpy. We might want the model to infer “never give the user instructions on bomb making”, but our dataset might only represent “be unhelpful about bomb making when in a single-shot prompt with short user queries”. This work builds intuition for when and why these spurious correlations arise.
Approaches like Constitutional AI4 or the Claude Soul Document5 are ways to specify the desired lessons more directly. But a better understanding of which features are most salient to a model during training could also help us design datasets and environments that more efficiently teach what we want.
Ultimately, we want to know which features our data best teaches the model to generalise from. This matters because post-training is currently done entirely by example — the intended lesson is never defined directly. A theory of generalisation in LLMs will require understanding when a model learns one feature versus another. Goodfire have written about a complementary direction: using model internals to shape learning directly6.
-
The Persona Selection Model: Why AI Assistants might Behave like Humans ↩︎
-
Chunky Post-Training: Data Driven Failures of Generalization (arXiv:2602.05910) ↩︎
-
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training (arXiv:2501.17161) ↩︎
-
Constitutional AI: Harmlessness from AI Feedback (arXiv:2212.08073) ↩︎